
A Basic Level Category Analysis with Commonsense Question Answering
A Basic Level Category Analysis with Commonsense Question Answering — Department of Electrical and Electronics Engineering, Bilkent University.
This term project focuses on measuring the common sense question answering performance of one of the GPT language models, GPT-3.5-turbo, by integrating a well-known language game, Family Feud. Common sense questions from the Family Feud dataset are posed to the language model to observe its answers and analyze the diversity and comprehensiveness of its responses. Additionally, basic level categories are researched using indicators such as word length, concreteness, age of acquisition and frequency to determine whether they are basic level category words or not. The aim is to create an environment that closely resembles real-life interactions and touch upon GPT language models.
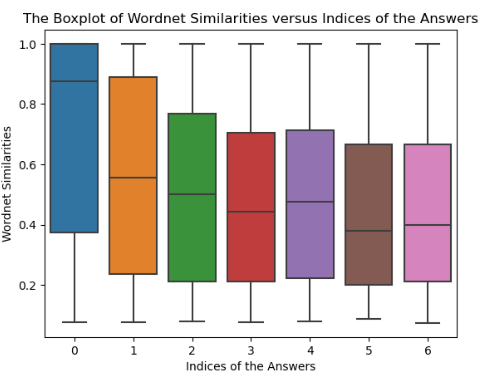
The similarity of GPT model’s answers with the real-life answers to commonsense questions.
Check out the source code.